PinnedPublished inTowards Data ScienceUnderstanding Flash Attention: Writing the Algorithm from Scratch in TritonFind out how Flash Attention works. Afterward, we’ll refine our understanding by writing a GPU kernel of the algorithm in Triton.Jan 15Jan 15
PinnedPublished inTowards Data ScienceSimple Ways to Speed Up Your PyTorch Model TrainingIf all machine learning engineers want one thing, it’s faster model training — maybe after good test metricsMay 28, 2024May 28, 2024
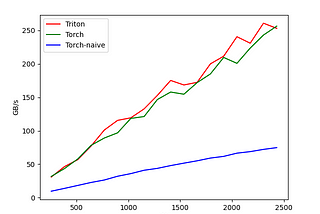
Published inTowards Data ScienceSpeed Up PyTorch With Custom Kernels. But It Gets Progressively DarkerWe’ll begin with torch.compile, move on to writing a custom Triton kernel, and finally dive into designing a CUDA kernel from scratch.Jan 9Jan 9
Published inLevel Up CodingSwift Actors — Common Problems and TipsSwift actors are a powerful tool to address data races and make your code thread-safeJun 15, 20231Jun 15, 20231
Moving from singletons to explicit dependencies is kind of a major professional growth in my…Jun 13, 2023Jun 13, 2023
Published inLevel Up CodingDive into Swift’s Memory ManagementSwift uses ARC to track and deallocate unused objects. Learn about the three types of reference counts and how ARC works — in this postJan 10, 2023Jan 10, 2023
Published inLevel Up CodingiOS App As a Microservice. Using SwiftUI in Modular AppOct 23, 2022Oct 23, 2022
Published inLevel Up CodingiOS App As a Microservice. Modularize Your App With TuistOct 10, 2022Oct 10, 2022